


No universo onde velocidade de decisão, colaboração inteligente e volume de dados caminham juntos, encontrar uma plataforma que una eficiência técnica e visão de negócio soa quase como um sonho antigo de qualquer gestor ou cientista de dados. Em nossa atuação na DW Intelligence, enxergamos a plataforma Databricks como um dos catalisadores dessa transformação.
Vamos mostrar, a partir da experiência de projetos e acompanhando tendências do mercado, como essa solução abraça a engenharia de dados, análise avançada e machine learning – tudo na nuvem.
Entendendo o conceito central do Databricks
O Databricks é uma plataforma unificada baseada em nuvem que centraliza, integra e simplifica fluxos de trabalho em ciência, engenharia e análise de dados. O objetivo é ir além da tradicional separação entre data lakes e data warehouses, criando um modelo conhecido como lakehouse.
Quando falamos em “unificar”, não estamos nos limitando à infraestrutura. O que vemos é um ambiente colaborativo, onde analistas, engenheiros e profissionais de negócio compartilham não apenas dados, mas também código, visualizações e insights – tudo de maneira segura e escalável.
Colaboração é a força motriz de times orientados por dados.
Nas reuniões internas da DW Intelligence, costumamos dizer que a funcionalidade de notebooks compartilhados e versionamento na nuvem transformaram a dinâmica entre as equipes técnicas. A curva de aprendizado, aliás, é suavizada por conta da interface intuitiva e da possibilidade de trabalhar com diferentes linguagens, como Python, SQL e Scala, no mesmo projeto.
A arquitetura lakehouse: integrando data lakes e data warehouses
Durante anos, o ecossistema de dados enfrentou o dilema entre flexibilidade e confiabilidade. Data lakes são excelentes para armazenar quantidades massivas de dados heterogêneos. Já os data warehouses destacam-se no tratamento de dados estruturados para análises rápidas.
O conceito de lakehouse, adotado pelo Databricks, une o melhor dos dois mundos ao:
- Permitir armazenar dados brutos e processados em um único repositório
- Oferecer recursos ACID para transações confiáveis (Atomicidade, Consistência, Isolamento, Durabilidade)
- Garantir governança sem sacrificar a flexibilidade
- Reduzir a redundância de dados e os custos de manutenção
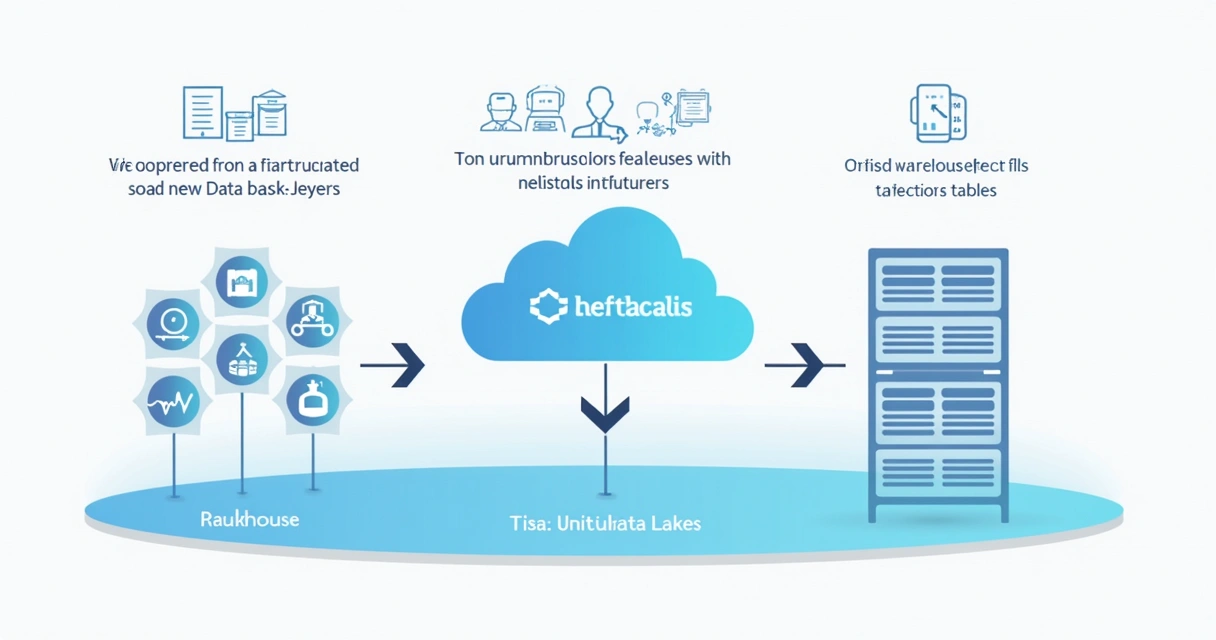
Essa abordagem já foi tema de artigo no blog da DW Intelligence, em nosso guia completo sobre data lakes, ilustrando como a arquitetura lakehouse apoia a modernização de pipelines, manutenção da qualidade e escalabilidade.
O papel do Apache Spark e do Delta Lake
Na essência de qualquer projeto de ciência de dados com Databricks está o Apache Spark. Ele realiza processamento distribuído de grandes volumes de informação, e isso representa múltiplos ganhos:
- Processamento paralelo, permitindo análises complexas em menor tempo
- Execução de tarefas em lote (batch) ou em fluxo (streaming)
- Rápida integração com APIs para machine learning, SQL, e grafos
Já o Delta Lake expande as capacidades do Spark, trazendo:
- Controle transacional para evitar dados corrompidos
- Rastreamento completo de versionamento dos dados
- Suporte a rollback e auditorias
Consistência, auditabilidade e desempenho em um só lugar.
Frequentemente, orientamos nossos clientes na DW Intelligence a estruturar pipelines de dados utilizando Spark+Delta Lake como base. Isso simplifica muito a gestão do ciclo de vida dos dados, inclusive para práticas de qualidade de dados em analytics.
Como construir pipelines práticos de engenharia e análise
Na prática do dia a dia, muita gente se pergunta: “Como conectamos nossas fontes, tratamos dados e entregamos valor no final?”
Um pipeline típico na plataforma unificada pode ser assim:
- Ingestão: Dados brutos chegam de APIs, bancos SQL, arquivos Parquet, logs etc.
- Transformação: Aplicação de regras de limpeza, junção, agregação e normalização no Spark.
- Armazenamento orquestrado: Registro confiável usando Delta Lake, com trilha de auditoria.
- Exploração analítica: Uso de notebooks e dashboards em SQL, Python ou R para visualização e modelagem.
- Entrega: Dados segmentados ou insights consumidos por BI ou aplicações externas via APIs.

Para quem quer aprender mais sobre arquitetura de engenharia de dados, sugerimos nosso guia de conceitos e ferramentas em engenharia de dados, que complementa bem as possibilidades do Databricks.
Aplicações reais: machine learning e análise em tempo real
Uma das maiores vantagens percebidas por nossos clientes é a possibilidade de passar rapidamente dos dados brutos ao insight previsível, ou mesmo à automação de decisões.
Alguns exemplos de aplicações que presenciamos em projetos com Databricks:
- Otimização logística: Modelos de machine learning detectando rotas mais rápidas, baseados em dados de GPS processados em tempo real.
- Detecção de fraudes financeiras: Streaming de transações com alertas automáticos via modelos treinados em Spark MLlib.
- Análise preditiva de demanda: Coleta e cruzamento de históricos de vendas para prever estoque ou campanhas de marketing.
Transformar dados em decisões automáticas muda o jogo da análise moderna.
Outro diferencial que observamos: a colaboração aumenta, pois engenheiros criam dados prontos para uso e analistas conseguem rapidamente criar, testar e revisar modelos no mesmo ambiente. Isso reduz o tempo de resposta e amplia o valor estratégico, uma meta constante em nossas parcerias na DW Intelligence.
Governança e segurança dos dados
Dados bem governados e protegidos são a base para qualquer analytics confiável. O Databricks oferece camadas de:
- Controle de acesso a nível de usuário, grupo e tabela
- Máscara de dados para proteger informações sensíveis
- Logs e auditoria para rastrear operações
- Conformidade com padrões como GDPR
A integração com ferramentas de automação e orquestração traz ainda mais transparência, facilitando auditorias e mitigando riscos internos. Para quem busca blindar projetos críticos, ter governança clara é um alívio – e já tivemos vários casos em que esse foi o fator de decisão para adoção da plataforma.
Escalabilidade, automação e integração multicloud
Uma das perguntas que mais ouvimos é: “Dá para começar pequeno e crescer depois?”. Em nossa experiência, a resposta é “sim”. Por funcionar em cima das maiores nuvens do mercado, é possível escalar clusters conforme a necessidade, automatizar jobs e integrar quase todos os tipos de fontes ou destinos de dados. Isso apoia equipes de todo tamanho, sem travas.
Entre as vantagens percebidas:
- Deploy automático de máquinas virtuais conforme a carga
- Flexibilidade para rodar workloads diversos (batch, streaming, ML)
- Migração ou conexão com diferentes provedores de nuvem
E tudo isso sem criar dependências tecnológicas que prendem o negócio, já que grande parte da base da plataforma é open source, como Apache Spark e Delta Lake.
Recursos de código aberto e treinamentos disponíveis
A base de código aberto é um dos pontos que mais valorizamos. Facilita inovação, reduz custos e mantém a comunidade ativa. O Databricks se apoia fortemente em frameworks abertos, como Delta Lake, MLflow e Spark Streaming.
Para quem quer aprender, há opções variadas de capacitação:
- Cursos digitais e presenciais oficiais
- Materiais gratuitos da comunidade open source
- Certificações para engenheiros, arquitetos e cientistas de dados
- Blogs especializados, como a categoria de engenharia de dados e análise de dados no blog da DW Intelligence
Conhecimento compartilhado expande horizontes na análise de dados.
Construindo valor com o Databricks
Ao longo de nossa trajetória na DW Intelligence, percebemos que o uso consistente da plataforma unificada transforma equipes. Os projetos não apenas aceleram, mas a própria cultura de decisão baseada em evidências se fortalece. Isso resulta em entregas mais rápidas, dados confiáveis e, no fim, decisões com efeito real no negócio.
Se seu objetivo for inovar, proteger e extrair valor dos dados, também pode ser hora de revisar processos e considerar essa abordagem.
Conclusão
O Databricks representa muito mais que apenas tecnologia: é uma ponte entre dados e ação. Combina processamento distribuído, governança, automação e colaboração numa arquitetura moderna. Na DW Intelligence, estamos prontos para te ajudar com insights, treinamentos ou implantação dessa solução – seja para quem está dando os primeiros passos, seja para quem busca escalar iniciativas já maduras.
Conheça nossos serviços, compartilhe suas dúvidas e vamos juntos descomplicar o universo dos dados para gerar decisões realmente impactantes. Entre em contato e descubra como tornar a análise de dados sua aliada estratégica!
Perguntas frequentes sobre Databricks
O que é a plataforma Databricks?
Databricks é uma plataforma na nuvem que une engenharia, ciência e análise de dados, integrando recursos de data lake e data warehouse na arquitetura lakehouse. Ela centraliza ingestão, processamento, ciência de dados, machine learning e visualização em um ambiente colaborativo e escalável.
Como usar Databricks para análise de dados?
O fluxo mais comum envolve criar notebooks interativos em Python, SQL, Scala ou R, processando dados via Apache Spark, armazenando de forma segura no Delta Lake e compartilhando dashboards ou resultados. Pipelines automatizados podem rodar ETLs, análises em tempo real e até alimentar modelos de machine learning.
Vale a pena investir no Databricks?
Se você busca escalabilidade, governança, integração multicloud, colaboração entre equipes e automação no ciclo de dados, a experiência que temos mostra que o retorno pode ser significativo. Para analytics moderno, é uma escolha estratégica.
Quais linguagens o Databricks suporta?
A plataforma trabalha principalmente com Python, SQL, Scala e R, e permite o uso conjunto dessas linguagens dentro dos notebooks. APIs e frameworks adicionais abrangem áreas como machine learning, streaming e grafos.
Quanto custa usar o Databricks?
O preço depende do plano escolhido (pay-as-you-go, assinaturas, etc.), número de usuários e volume de processamento (clusters). É possível começar pequeno e escalar. Muitas organizações iniciam com uso projetado e ajustam recursos conforme a demanda aumenta.


